Migrating from Google Sheets to AWS DynamoDB
So you used Google Sheets as a database. Whoops. Here's what Wrapmate did to migrate from a spreadsheet to DynamoDB.


Guest post time! The following blog post was written by Kristen Chase, one of the software engineers at Wrapmate.
In this blog post, I will delve into the journey of optimizing our customer creative brief processing system at Wrapmate. By replacing Google Sheets with AWS DynamoDB, we were able to drastically improve efficiency and reduce processing time. Join me as I take you on a journey through the challenges we faced, the innovative solutions we implemented, and the remarkable results we achieved.
From Typeform to Notion
Before we can start working on a customer’s vehicle wrap we need some basic information. We ask customers to complete a “Creative Brief.” Customers submit creative briefs via Typeform, and they typically include anywhere from 5 to 15 attached images.

The plan was simple: get that submitted Creative Brief into a place that was easily accessible to the Wrapmate Operations team. For saving & viewing the creative brief, we chose Notion (we ❤️ Notion!), and would store a back-up of the submitted photo in our company's Google Drive.
We hit a snag early on with development: we discovered that the absolute URLs to each submitted image (when accessed via Typeform) were behind bearer-token authorization. This meant publicly accessible requests to the URLs would fail. Unfortunately for us, this prevented Notion from automatically unfurling the embedded image in the newly created Notion page. In order for Notion to automatically unfurl a link to an image, that image must be publicly accessible.
Version 1, therefore, led us to implement a multi-step process:
- The user submits the Typeform,
- automation catches this submission and creates an initial Notion page, keeping references to the Typeform-hosted images and makes a record of how many files need to be processed,
- automation detects when URLs need to be converted from Typeform to a publicly accessible URL (we used S3), then migrates each file asynchronously,
- automation continually checks in with HubSpot to determine if the next incomplete creative brief is ready to be finalized – checking the
file_counton the Deal against thefile_countcalculated across all records submitted, and - if it determines all files are processed and finalization is ready to proceed, automation kicks off a finalization process that updates the original page with a custom block of content including references to the respective images' public URLs, thereby triggering Notion into automatically unfurling those images in the page itself.
Easy, right? All we needed to do was pick a database that would act as the go-between, tracking new submissions, which files needed migration, and marking them as "done" each time a file migration completed successfully.
The problem was that the database chosen...was Google Sheets. 😓
Backing Up the Pipe
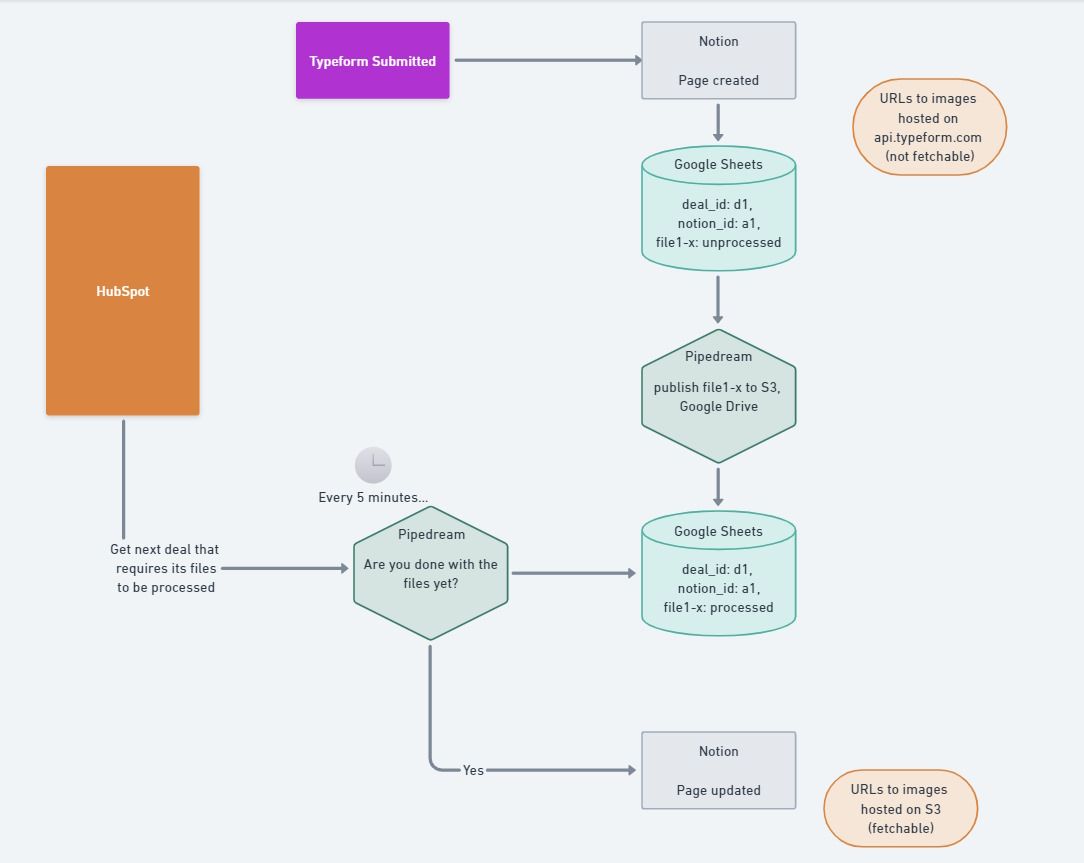
In version 1, the number of images to be processed (file_count) was saved in HubSpot, in the customer’s Deal object. Each processed file's URL was recorded in a new row in an ever growing Google Sheet along with its corresponding HubSpot Deal id.
Finalizing the record required multiple Pipedream workflows that ran on five minute intervals. One workflow was tasked with finding the next HubSpot Deal with a non-zero file_count. This workflow counted the number of rows in the Google Sheet with the same Deal id. If the file processing was complete, the counts would match, and the creative brief record would be finalized. But this was not without issue, as we quickly discovered.
Occasionally, the counts would never match due to a variety of issues, the most common of which was multiple creative briefs attempting to update the same row of the Google Sheet concurrently. This was our version of a "deadlock": a single creative brief would remain in a state of limbo, never processing fully, and never getting out of the way. So, newly submitted creative briefs would come in and immediately join the pile, as the pipe backed up further and further.
Even without the artificially induced bottleneck (of managing HubSpot's API limits, which deserves its own blog post), the entire process typically took anywhere from 15 to 30 minutes and there were over 12,000 rows in our expanding Google Sheet. We were nearly halfway to the limit of 40,000! It was clear that Google Sheets wasn’t a long-term solution...or even a very robust one, mid-term.
The Migration to AWS DynamoDB
Once we dedicated resources to remove our dependency to Google Sheets, it was time to choose an actual database. Our creative brief submission and processing system (code-named "Homologate") needed a database that would support fast writes, provide better consistency than a spreadsheet, and could emit update events to reduce or eliminate our need to constantly query HubSpot.
We looked no further than AWS DynamoDB. Part of our monolith was already hosted in AWS, so this made perfect sense for us. That same monolith already supported an event bus via SNS, and being able to emit events based off of changes in DynamoDB set the stage for a much-needed refactoring. In going this route, we were able to move code out of Pipedream and into our codebase where it belonged.
With a real database in tow, we implemented a design that follows the standard adjacency model: rather than writing rows of data to Google Sheets, then cross-referencing those rows with a value stored in HubSpot, we write a customerFileMonitor row for each customer submission and a customerFileQueue row for each image file, storing various attributes (see diagram below).
After the user submits a Typeform, we still employ an automation to catch the submission, create an initial Notion page and keep references to the images (hosted in Typeform). Now, however, instead of storing the file_count in HubSpot, we create a customerFileMonitor record and store how many files need to be processed there under fileCount.
Once each image file is processed, it is handed off to a workflow that creates the customerFileQueue record, and uses its parent_id to link back to the customerFileMonitor record via the unique id attribute. The creation of this record generates an SNS message with the subject of MSG_HOMOLOGATE_NEW_RECORD.

When this SNS message is received, a function is immediately triggered from our monolith that:
- saves the image to the associated Notion page, and
let fieldName = record.fieldName;
let shareableLink = record.shareableLink;
let notionPageId = record.notionPageId;
var notionUpdate = await retry(
async () => {
return await updateNotion(fieldName, shareableLink, notionPageId);
},
{
retries: 3,
minTimeout: 1000,
maxTimeout: 5000,
onRetry: (err, attempt) => {
console.log(
`Retrying updateNotion. Attempt ${attempt} failed with error: ${err}`,
);
},
},
);
2. updates the customerFileQueue property notionRecordUpdated to true.
const dynamoParams = buildDBParams(
{ id: record.id, type: "customerFileQueue" },
recordData,
HOMOLOGATE_TABLE,
expirationDate
);
let dbUpdate = await dbClient.update(dynamoParams).promise();
Modification to any record in our new database triggers a second SNS message with the subject of MSG_HOMOLOGATE_UPDATED_CUSTOMER_RECORD. When this message is received – once it is confirmed that the record updated was of type customerFileQueue – a different function fires, which is responsible for:
- looking up the file count from the associated
customerFileMonitorrecord,
let customerFileMonitorId = record.parentId;
let params = {
TableName: HOMOLOGATE_TABLE,
KeyConditionExpression: 'id = :id ',
ExpressionAttributeValues: {
':id': customerFileMonitorId,
},
};
let { Items } = await dbClient.query(params).promise();
const monitorRecord = Items[0];
const fileCount = monitorRecord.fileCount;
2. counting existing customerFileQueue records that have a matching parentFolderId and a notionRecordUpdated property that is set to true and, if the count matches, finalizes the record, and
let parentId = record.parentId;
let queueQryParams = {
TableName: HOMOLOGATE_TABLE,
ReturnConsumedCapacity: 'TOTAL',
Limit: 50,
KeyConditionExpression: '#kn0 = :kv0',
IndexName: 'type-id-index',
FilterExpression: '#n0 = :v0 AND #n1 = :v1',
ExpressionAttributeNames: {
'#n0': 'parentId',
'#n1': 'notionRecordUpdated',
'#kn0': 'type',
},
ExpressionAttributeValues: {
':v0': parentId,
':v1': true,
':kv0': 'customerFileQueue',
},
};
let queueItems = [];
let lastEvaluatedKey = null;
do {
const queryResponse = await dbClient
.query({
...queueQryParams,
ExclusiveStartKey: lastEvaluatedKey,
})
.promise();
queueItems = queueItems.concat(queryResponse.Items);
lastEvaluatedKey = queryResponse.LastEvaluatedKey;
} while (lastEvaluatedKey);
if (queueItems.length === fileCount){
//continue
}3. finishes by updating the HubSpot Deal:
const hs_dealUpdateEndpoint = `https://api.hubapi.com/crm/v3/objects/deals/${dealId}`;
const dealProperties = {
completed_typeform: true,
};
const postData = {
properties: dealProperties,
};
const hsRes = await fetch(hs_dealUpdateEndpoint, {
method: 'PATCH',
body: JSON.stringify(postData),
headers: hs_headers,
});
var hubspotResult = await hsRes.json();
if (hubspotResult.id) {
try {
const res = await fetch(zapEndpoint_MSG_FINALIZE_NOTION_RECORD, {
method: 'POST',
body: JSON.stringify({
deal_id: dealId,
notion_record_id: record.notionPageId,
}),
headers: {
Accept: 'application/json, text/plain, */*',
'User-Agent': '*',
},
});
var result = await res.json();
return result;
} catch (e) {
console.log('error', e);
return e;
}
}Remarkable Results
Recall that version 1's entire process (from Typeform submission to fully processed Notion page) took anywhere between 20-30 minutes. This was primarily due to leaning on HubSpot as a method of managing the creative brief's record state – its file_count. By depending on HubSpot – and being subject to its rate limits – we were forced to inject artificial delays along each step of this process.
By refactoring HubSpot out and moving us to a pub/sub event bus, the entire process now completes in 2 to 3 minutes. The majority of that time is now simply waiting for all of the files to migrate from Typeform to S3!
The system processes creative briefs so quickly, in fact, we've had to make a number of post-version 2 adjustments. For example, we exceeded the limit of queries per minute set by the Google Drive API (remember we mirror to it as well?) Additionally, we've added delays – as well as the “Retry” Node module (see above) – to handle the back-to-back requests sent to the Notion API. Yes, we traded "too fast for HubSpot" for "too fast for Notion and Google Drive." 🤗
Since the implementation of version 2, no erroneous execution has "backed up the pipe" and prevented the finalization of subsequent submitted creative briefs.
Just Say No to Google Sheets (as a Database)
Our transition from Google Sheets to AWS DynamoDB revolutionized our customer brief processing system. By building atop a real database, eliminating bottlenecks, embracing event-driven architecture, and leveraging automation, we achieved remarkable efficiency gains. The entire process now takes just a fraction of the time, allowing our Operations team to serve our customers faster. And in this business, every second counts.
La elección de cómo comparar tallas de una camiseta de portero mejora al comparar la guía de tallas y una camiseta que ya quede bien. Las fotografías y la ficha del producto deberían confirmar las condiciones de cambio cuando el ajuste no sea el esperado.


